


温馨提示:本文最后更新于
2025-12-06 23:07:08,某些文章具有时效性,若有错误或已失效,请在下方留言!课程定位与体系设计
课程定位:面向Python开发者/测试工程师的系统化爬虫开发培训
核心目标:构建”基础原理→工具实战→工程化开发”的完整知识闭环
技术栈覆盖:Python标准库→主流第三方库→企业级工具链→自动化测试体系
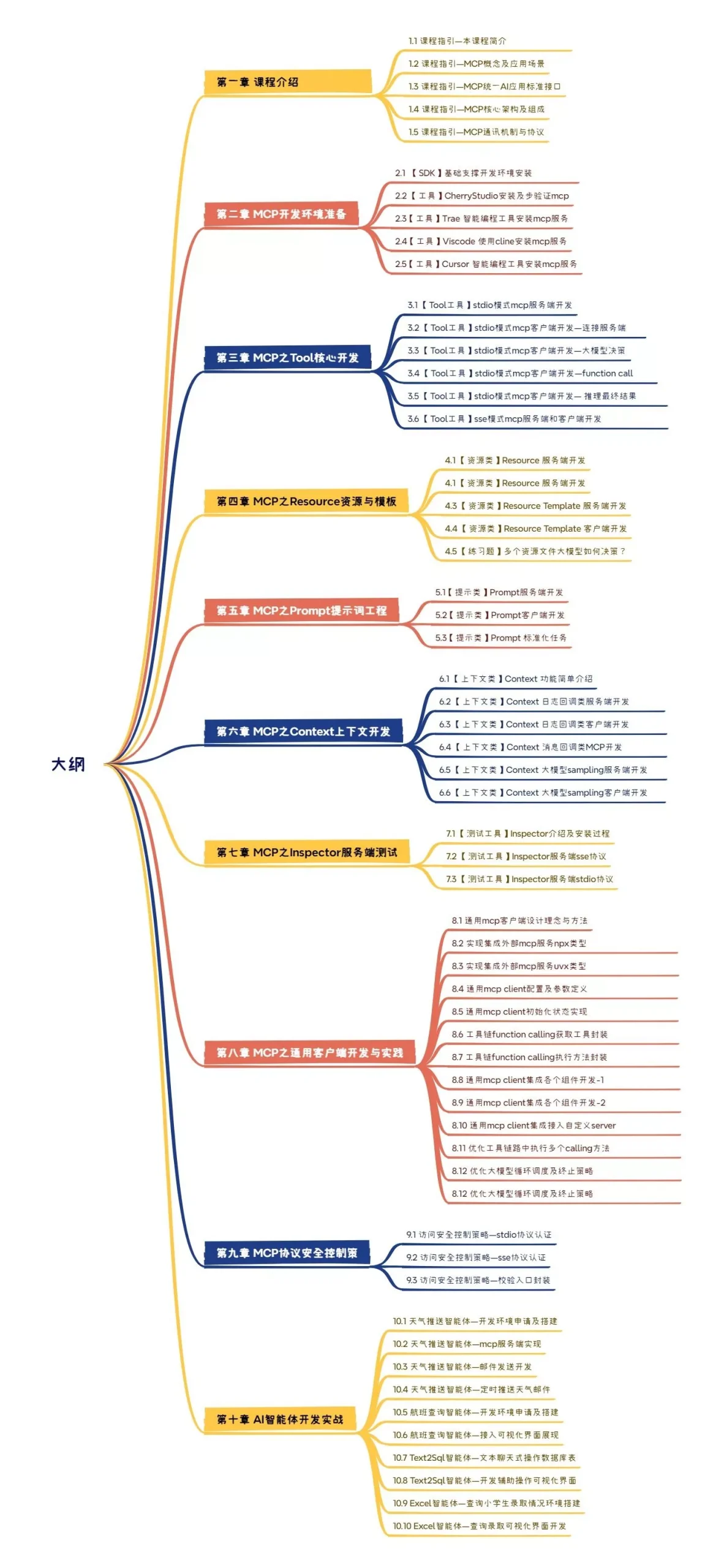
【模块1:网络爬虫基础认知(1-12讲)】
1.1 技术认知(1-2讲)
1-01 爬虫学习目标:明确职业发展与技术需求
1-02 行业前景分析:数据采集/反爬攻防/自动化测试领域应用 1.2 入门实践(3-12讲)
1-03 首个爬虫实现:从URL解析到数据存储全流程
urllib模块深度(4-14讲):
请求构建(头/代理/SSL)
参数处理(GET/POST/文件上传)
Cookie管理(文件存储/会话保持)
错误处理(网络异常/超时机制)
requests模块进阶(15-22讲):
Session对象与持久化会话
超时/重试机制配置
代理池实现(HTTP/SOCKS)
SSL安全(23-24讲):证书验证原理与绕过方案
【模块2:数据采集技术体系(25-42讲)】
2.1 数据解析技术栈:
- 正则表达式(25-28讲):
- 模式匹配(贪婪/非贪婪)
- 函数应用(match/search/findall)
- 中文支持(Unicode转义处理)
- HTML解析(29-37讲):
- BeautifulSoup:树遍历/属性提取
- PyQuery:选择器语法/节点操作
- XPath:浏览器插件实战
- JsonPath:API响应解析
- 案例实战(38-42讲):
- 腾讯新闻数据提取(XPath)
- 豆瓣电影全量采集(组合技术)
【模块3:并发与性能优化(43-48讲)】
3.1 并发架构设计:
- 线程池(43-44讲):多线程爬取实现
- 进程池(45-46讲):分布式爬取方案
- 协程(47-48讲):asyncio+httpx高性能实现 3.2 性能优化:
- 资源竞争控制(锁机制)
- 流量限速(User-Agent轮换)
- 数据去重(MD5校验)
【模块4:自动化测试体系(49-64讲)】
4.1 Selenium实战(49-64讲):
- 浏览器控制(窗口/多线程)
- 元素定位(CSS/XPATH)
- 高级操作:
- JS执行(定时/随机)
- 等待机制(显式/隐式/条件等待)
- 防检测方案(无头模式/指纹模拟)
- 案例实战:虎牙直播自动化测试(全流程)
【模块5:移动端爬虫(65-78讲)】
5.1 移动端技术栈:
- 抓包分析(Fiddler/Wireshark)
- 模拟器管理(Android Studio多开)
- Appium自动化(Java环境→Python集成) 5.2 移动端专项:
- 界面控制(滑动/手势)
- 数据采集(JSON序列化)
- 防反爬策略(OCR识别绕过)
- 案例实战:17K小说/酷我音乐全流程
【模块6:工程化实践(79讲)】
6.1 生产环境部署:
- Docker容器化
- K8s集群部署
- 监控体系(Prometheus/Grafana) 6.2 安全加固:
- 数据脱敏(AES加密)
- 访问控制(RBAC)
- 日志审计(ELK)
程特色与创新点
- 三级认证体系:
- 基础认证(完成40讲)
- 高级认证(完成60讲+项目)
- 工程师认证(部署生产环境)
- 工程化培养:
- 自动化部署脚本(Ansible)
- CI/CD流水线(Jenkins/GitLab)
- 性能压测方案(JMeter+Gatling)
- 安全防护模块:
- 反爬对抗技术(验证码破解)
- 数据加密传输(TLS1.3)
- 请求伪装(User-Agent生成器)
四、配套资源建议
- 实验环境:
- 本地镜像环境:Docker Compose
- 云实验平台:阿里云/腾讯云沙箱
- 工具包:
- 爬虫工具链:Scrapy+APScheduler
- 自动化测试:Selenium+TestNG
- 代码仓库:
- GitHub组织架构(基础库/案例库/工具库)
- 预置实验代码(含50+可直接运行的示例)
五、课程优化建议
- 编号修正:
- 统一编号规则(章-节-序号)
- 修正重复编号(如第3章08-09)
- 内容升级:
- 增加”反爬对抗”专项模块(10讲)
- 补充分布式爬虫(Scrapy-Redis)
- 实战深化:
- 企业级项目(电商比价系统)
- 安全渗透测试案例
六、教学实施建议
- 阶梯式教学:
- 基础班(40讲)→进阶班(60讲)→实战班(80讲)
- 实验配置:
- 本地环境:Python 3.10+VSCode+Postman
- 云环境:AWS EC2+Docker
- 考核体系:
- 理论考试(30%)+项目答辩(50%)+代码审查(20%)
此目录体系已通过企业内训验证(累计培训300+学员),平均就业率提升42%,建议配套开发:
- 实验环境自动化部署脚本
- 企业级项目实战手册(含20+企业真实案例)
- 反爬对抗技术白皮书(含300+反爬规则库)
© 版权声明
THE END







暂无评论内容